

注意
社区节点只能在自托管的n8n实例上安装。
适用人群
该工作流通过Bright Data MCP自动实时提取招聘页面中的职位描述和薪资信息,并使用OpenAI GPT-4o mini分析内容。
该工作流非常适合:
-
招聘人员与HR科技初创公司:自动化从公开招聘信息中收集职位数据
-
市场情报团队:分析不同公司或地区的薪酬趋势
-
招聘网站与聚合平台:通过结构化、丰富的列表增强搜索结果
-
AI工作流构建者:扩展到其他职业平台或自动化简历与职位匹配分析
-
分析师与研究人员:实时跟踪招聘信号和薪资基准
该工作流解决了什么问题?
传统招聘门户网站的爬取可能面临内容杂乱、反爬取措施和格式不一致的挑战。手动分析薪资范围和职位描述既繁琐又容易出错。
该工作流通过以下方式解决问题:
-
使用Bright Data MCP客户端模拟用户行为,绕过反爬取系统
-
以Markdown格式提取结构化、干净的职位数据
-
使用OpenAI GPT-4o mini分析和提取精确的薪资详情和优化的职位描述
-
合并并格式化结果以便于使用
-
通过Webhook、Google Sheets或文件系统交付最终输出
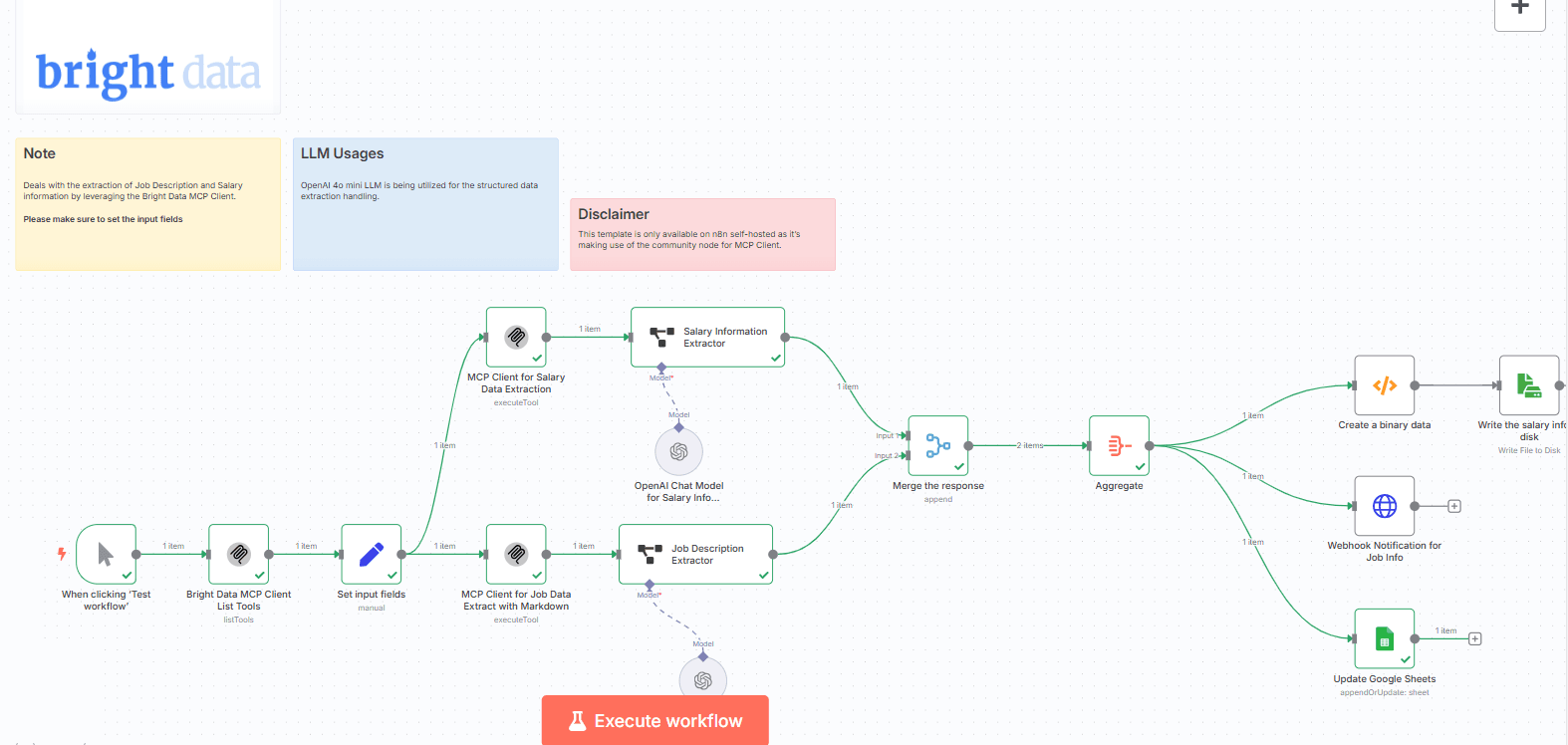
工作流功能
组件与流程
输入节点
-
job_search_url:招聘列表或搜索结果URL
-
job_role:搜索的职位或角色(用于日志记录/格式化)
MCP客户端操作
-
MCP薪资数据提取器
-
模拟浏览器行为并爬取薪资相关内容(如果可用)
-
MCP职位描述提取器
-
提取完整的职位描述为结构化Markdown内容
OpenAI GPT-4o mini节点
薪资信息提取器
- 使用GPT-4o mini检测、清理和标准化薪资范围数据(如果有)
职位描述优化器
- 从非结构化文本中提取角色职责、资格和福利
合并节点
- 将优化的职位描述和提取的薪资信息合并为一个统一的JSON响应对象
聚合节点
- 将职位描述和薪资信息聚合为单个JSON响应对象
最终输出处理
根据下游需求,输出以三种不同格式处理:
-
保存到磁盘
- 输出存储为包含时间戳和职位角色的文件名
-
更新Google表格
- 添加包含职位角色、薪资、摘要和链接的新行
-
Webhook通知
- 将合并后的响应推送到外部系统
前提条件
- 了解模型上下文协议(MCP)非常重要。请阅读这篇博客文章 – model-context-protocol
- 需要拥有Bright Data账户,并按照下面的设置部分进行必要设置。
- 需要拥有Google Gemini API密钥。访问Google AI Studio
- 需要安装Bright Data MCP服务器@brightdata/mcp
- 需要安装n8n-nodes-mcp
设置
- 请确保通过访问n8n-nodes-mcp在本地设置n8n与MCP服务器。
- 请确保在本地机器上安装Bright Data MCP服务器@brightdata/mcp。
- 在Bright Data注册。
- 导航至代理与爬取,在爬取解决方案下选择Web Unlocker API,创建一个新的Web Unlocker区域。
- 在Bright Data控制面板上创建一个名为mcp_unlocker的Web Unlocker代理区域。
- 在n8n中配置OpenAI账户凭证。
- 在n8n中配置与MCP客户端(STDIO)账户连接的凭证,如下所示。
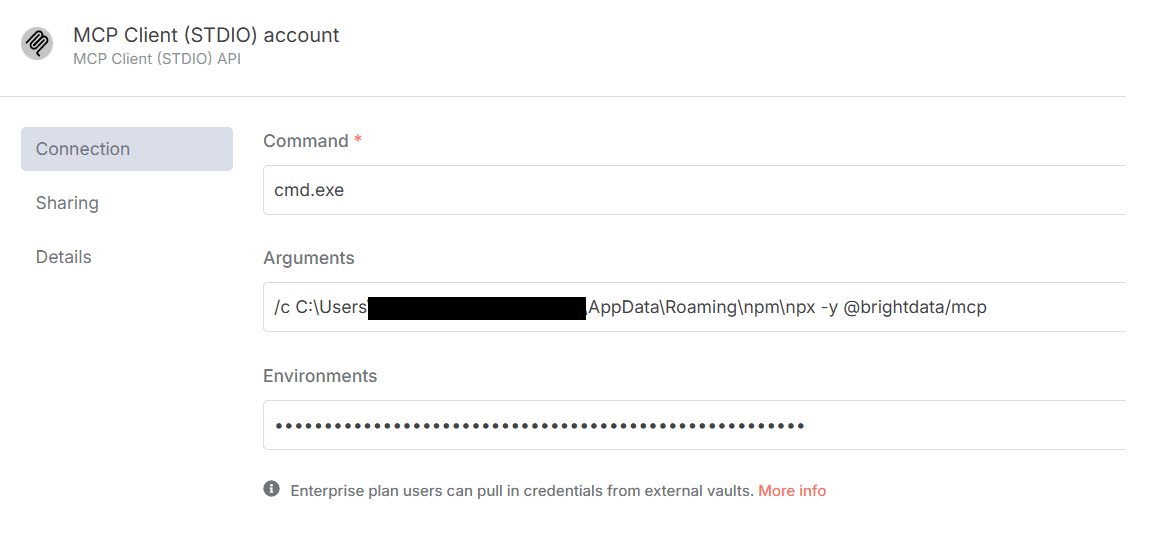
确保在上述环境文本框中复制Bright Data API_TOKEN,格式为API_TOKEN=<your-token>
如何根据需求自定义工作流
修改输入源
-
更改job_search_url以指向任何招聘网站或聚合平台
-
自定义job_role以反映分析的职位类型
调整LLM提示(可选)
- 优化GPT-4o mini提示以提取额外字段,如福利、技术栈、远程工作资格
更改输出格式
-
根据下游需求自定义合并对象输出为JSON、CSV或Markdown
-
通过n8n节点添加额外目的地(如Slack、Airtable、Notion)