
谷歌 Gemini 目前提供三种使用和体验方式:
方式一: Bard
谷歌已经将Gemini集成到最新版Bard聊天机器人中,网址: https://bard.google.com
集成Gemini后使得Bard具有强大的多模态理解能力。Bard 通过集成 Gemini,能更好地理解和处理文本、图像、音频和视频等多种信息类型。
Bard 集成 Gemini 后,能够实现以下功能:
- 更好地理解文本的含义,并对其进行问答、翻译、摘要等操作。
- 更好地理解图像的内容,并对其进行分类、描述、标注等操作。
- 更好地理解音频的内容,并对其进行分类、识别、转录等操作。
- 更好地理解视频的内容,并对其进行分类、描述、生成等操作。
例如,Bard 可以使用 Gemini 来理解以下场景:
- 您问 Bard:“这张图片是什么?”Bard 可以使用 Gemini 来理解图片的内容,并回答您:“这张图片是一只狗。”
- 您问 Bard:“这段音频的内容是什么?”Bard 可以使用 Gemini 来理解音频的内容,并回答您:“这段音频是一段新闻报道。”
- 您问 Bard:“这段视频的内容是什么?”Bard 可以使用 Gemini 来理解视频的内容,并回答您:“这段视频是一段体育比赛。”
Bard 集成 Gemini 还在开发中,未来还将有更多的功能和改进。
方式二: Google Cloud Vertex AI


Google Cloud Vertex AI是一个企业级人工智能平台,可用于构建、训练和部署机器学习模型。Gemini 模型可通过 Google Cloud Vertex AI 进行访问和使用. 访问网址:https://cloud.google.com/?hl=zh-CN
使用 Google Cloud Vertex AI 注册和使用 Gemini,请按照以下步骤操作:
- 创建一个 Google Cloud 帐户。
- 启用 Google Cloud Vertex AI 服务。
- 创建一个 Vertex AI 项目。
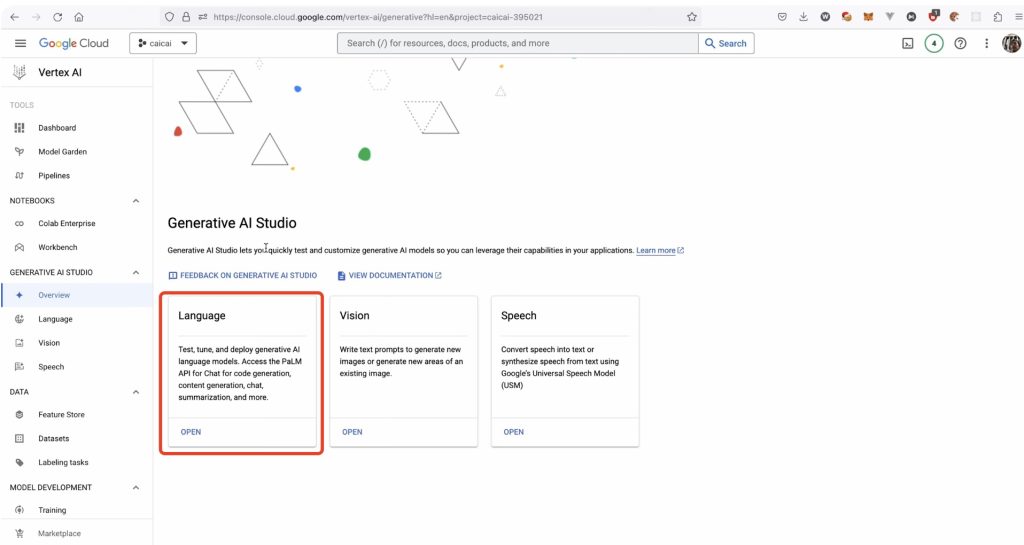
- 在“模型”选项卡中,搜索“Gemini”。
- 选择您要使用的 Gemini 模型。
- 点击“创建新模型”按钮。
- 为您的模型输入名称和描述。
- 点击“创建”按钮。
您的模型将创建并启动。您可以使用 Gemini 模型来构建和部署您的应用程序。
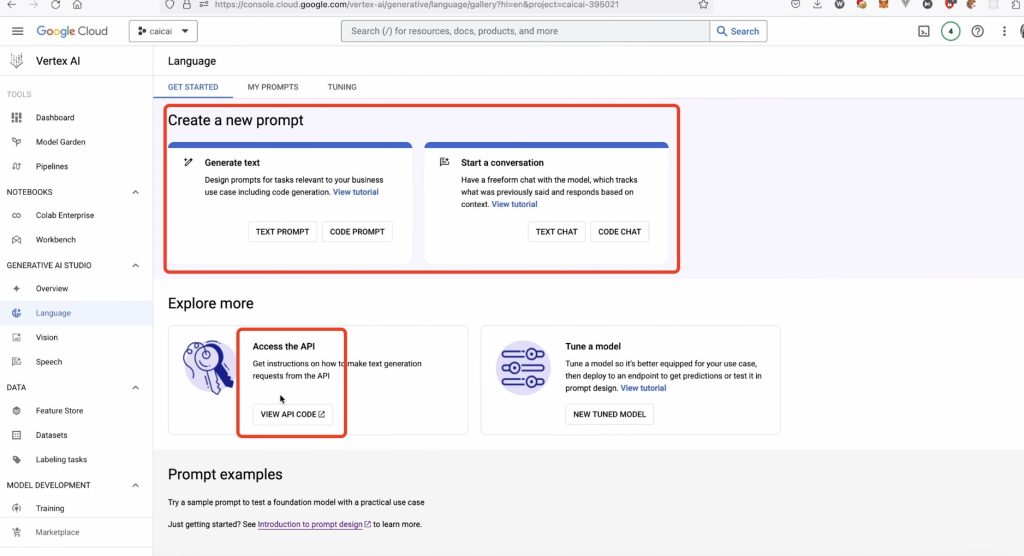
Vertex AI PaLM API 可让您测试、自定义和部署 Google PaLM 2 大型语言模型 (LLM) 的实例,以便您可以在应用程序中利用 PaLM 2 的功能。PaLM 2 系列模型支持文本完成、多轮聊天和文本嵌入生成。本页面向您展示如何快速开始使用所有三个用例。
要开始使用 Vertex AI PaLM API,请通过执行以下操作转到 Cloud Shell:
- 转到 Google Cloud 控制台。
- 单击右上角的终端 “激活 Cloud Shell”图标。现在您已准备好开始使用对 PaLM API 运行curl 命令。
尝试文字提示
参数定义
下表显示了需要为文本的 Vertex AI PaLM API 配置的参数:
| 范围 | 描述 | 可接受的值 |
|---|---|---|
prompt | 用于生成模型响应的文本输入。提示可以包括序言、问题、建议、说明或示例。 | 文本 |
temperature | 温度用于在响应生成期间进行采样,这在应用topP 和时发生。topK温度控制着代币选择的随机程度。较低的温度适合需要较少开放性或创造性反应的提示,而较高的温度可以带来更加多样化或创造性的结果。温度意味着0 始终选择概率最高的标记。在这种情况下,对给定提示的响应大多是确定性的,但仍然可能存在少量变化。对于大多数用例,请尝试从温度开始0.2。如果模型返回的响应太通用、太短,或者模型给出后备响应,请尝试提高温度。 | 0.0–1.0Default: 0 |
maxOutputTokens | 响应中可以生成的最大令牌数。为较短的响应指定较低的值,为较长的响应指定较高的值。 令牌可能比单词小。一个令牌大约有四个字符。100 个标记对应大约 60-80 个单词。 | 1–1024Default: 0 |
topK | Top-k 改变了模型选择输出标记的方式。top-k 为 1 表示所选标记是模型词汇表中所有标记中最有可能的标记(也称为贪婪解码),而 top-k 为 3 表示从 3 个最可能的标记中选择下一个标记(使用温度)。对于每个令牌选择步骤,都会对概率最高的 顶部令牌进行采样。然后根据使用温度采样选择的最终令牌 K进一步过滤令牌。 为较少的随机响应指定较低的值,为较多的随机响应指定较高的值。topP | 1–40Default: 40 |
topP | Top-p 改变模型选择输出标记的方式。从概率最大到最小的 K 个(参见 topK 参数)中选择令牌,直到它们的概率之和等于 top-p 值。例如,如果标记 A、B 和 C 的概率为 0.3、0.2 和 0.1,并且 top-p 值为 0.5,则模型将选择 A 或 B 作为下一个标记(使用温度),并且不会选择 A 或 B 作为下一个标记。 t 考虑 C。默认的 top-p 值为 0.95。 为较少的随机响应指定较低的值,为较多的随机响应指定较高的值。 | 0.0–1.0Default: 0.95 |
示例文本提示
选择以下选项卡之一并复制配置了项目 ID 的示例文本提示。将提示粘贴到 Cloud Shell 中以查询模型以获得响应。总结分类情感分析萃取构思
MODEL_ID="text-bison"
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:predict -d \
$'{
"instances": [
{ "prompt": "Provide a summary with about two sentences for the following article:
The efficient-market hypothesis (EMH) is a hypothesis in financial \
economics that states that asset prices reflect all available \
information. A direct implication is that it is impossible to \
\\"beat the market\\" consistently on a risk-adjusted basis since market \
prices should only react to new information. Because the EMH is \
formulated in terms of risk adjustment, it only makes testable \
predictions when coupled with a particular model of risk. As a \
result, research in financial economics since at least the 1990s has \
focused on market anomalies, that is, deviations from specific \
models of risk. The idea that financial market returns are difficult \
to predict goes back to Bachelier, Mandelbrot, and Samuelson, but \
is closely associated with Eugene Fama, in part due to his \
influential 1970 review of the theoretical and empirical research. \
The EMH provides the basic logic for modern risk-based theories of \
asset prices, and frameworks such as consumption-based asset pricing \
and intermediary asset pricing can be thought of as the combination \
of a model of risk with the EMH. Many decades of empirical research \
on return predictability has found mixed evidence. Research in the \
1950s and 1960s often found a lack of predictability (e.g. Ball and \
Brown 1968; Fama, Fisher, Jensen, and Roll 1969), yet the \
1980s-2000s saw an explosion of discovered return predictors (e.g. \
Rosenberg, Reid, and Lanstein 1985; Campbell and Shiller 1988; \
Jegadeesh and Titman 1993). Since the 2010s, studies have often \
found that return predictability has become more elusive, as \
predictability fails to work out-of-sample (Goyal and Welch 2008), \
or has been weakened by advances in trading technology and investor \
learning (Chordia, Subrahmanyam, and Tong 2014; McLean and Pontiff \
2016; Martineau 2021).
Summary:
"}
],
"parameters": {
"temperature": 0.2,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}'尝试聊天提示
对于聊天 API 调用,context、examples和messages组合起来形成提示。下表显示了需要为文本的 Vertex AI PaLM API 配置的参数:
| 范围 | 描述 | 可接受的值 |
|---|---|---|
context(选修的) | 上下文决定了模型在整个对话过程中的响应方式。例如,您可以使用上下文来指定模型可以或不能使用的单词、要关注或避免的主题,或者响应格式或风格。 | 文本 |
examples(选修的) | 发送给模型的结构化消息列表,以了解如何响应对话。 | List[Structured Message] “input”: {“content”: “provide content”}, “output”: {“content”: “provide content”}} |
messages(必需的) | 对话历史记录以结构化的替代作者形式提供给模型。消息按时间顺序显示:最旧的在前,最新的在最后。当消息历史记录导致输入超过最大长度时,最旧的消息将被删除,直到整个提示在允许的限制内。 | List[Structured Message] “author”: “user”, “content”: “user message”,} |
temperature | 温度用于在响应生成期间进行采样,响应生成在应用topP和时发生。topK温度控制着代币选择的随机程度。较低的温度适合需要更具确定性和较少开放性或创造性响应的提示,而较高的温度可以带来更加多样化或创造性的结果。温度 0 是确定性的:始终选择最高概率的响应。对于大多数用例,请尝试从 0.2 的温度开始。 | 0.0–1.0Default: 0 |
maxOutputTokens | 响应中可以生成的最大令牌数。为较短的响应指定较低的值,为较长的响应指定较高的值。 令牌可能比单词小。一个令牌大约有四个字符。100 个标记对应大约 60-80 个单词。 | 1–1024Default: 0 |
topK | Top-k 改变了模型选择输出标记的方式。top-k 为 1 表示所选标记是模型词汇表中所有标记中最有可能的标记(也称为贪婪解码),而 top-k 为 3 表示从 3 个最可能的标记中选择下一个标记(使用温度)。对于每个令牌选择步骤,都会对概率最高的 顶部令牌进行采样。然后根据使用温度采样选择的最终令牌 K进一步过滤令牌。 为较少的随机响应指定较低的值,为较多的随机响应指定较高的值。topP | 1–40Default: 40 |
topP | Top-p 改变模型选择输出标记的方式。从概率最大到最小的 K 个(参见 topK 参数)中选择令牌,直到它们的概率之和等于 top-p 值。例如,如果标记 A、B 和 C 的概率为 0.3、0.2 和 0.1,并且 top-p 值为 0.5,则模型将选择 A 或 B 作为下一个标记(使用温度),并且不会选择 A 或 B 作为下一个标记。 t 考虑 C。默认的 top-p 值为 0.95。 为较少的随机响应指定较低的值,为较多的随机响应指定较高的值。 | 0.0–1.0Default: 0.95 |
聊天提示示例
在以下选项卡之一中复制示例聊天提示并配置您的项目 ID。将提示粘贴到 Cloud Shell 中以查询模型以获得响应。聊天提示#1聊天提示#2
MODEL_ID="chat-bison"
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:predict -d \
'{
"instances": [{
"context": "My name is Ned. You are my personal assistant. My favorite movies are Lord of the Rings and Hobbit.",
"examples": [ {
"input": {"content": "Who do you work for?"},
"output": {"content": "I work for Ned."}
},
{
"input": {"content": "What do I like?"},
"output": {"content": "Ned likes watching movies."}
}],
"messages": [
{
"author": "user",
"content": "Are my favorite movies based on a book series?",
}]
}],
"parameters": {
"temperature": 0.3,
"maxOutputTokens": 200,
"topP": 0.8,
"topK": 40
}
}'尝试获取文本嵌入
Vertex AI PaLM Embedding API 执行在线(实时)预测,以从输入文本中获取嵌入。
该 API 最多接受 3,072 个输入标记并输出 768 维向量嵌入。
请求和响应
请求正文
请求正文包含具有以下结构的数据:
| JSON 表示 |
|---|
| { “instances”: [ {“content”: “text to generate embeddings”} ] } |
| 领域 | |
|---|---|
| 实例 | 值(值格式) 必填。输入到预测调用的实例。 注意:API 目前限制每次调用最多发送两个示例。 实例的模式是通过 Endpoint 的 DeployedModels 的Model 的 PredictSchemata 的 instanceSchemaUri指定的。 |
响应体
如果成功,响应正文包含具有以下结构的数据:
PredictionService.Predict的响应消息。
| JSON 表示 |
|---|
| { “predictions”: [ { “embeddings”: { “values”: [0.000001, …, 0.000001] } } ], “deployedModelId”: string, “model”: string, “modelVersionId”: string, “modelDisplayName”: string } |
| 领域 | |
|---|---|
| 预测 | value(值格式) 作为预测调用的输出的预测。 任何单个预测的模式可以通过 Endpoint 的 DeployedModels 的Model 的 PredictSchemata 的 PredictionSchemaUri来指定。 |
| 已部署模型ID | 提供此预测的端点的 DeployedModel 的字符串ID。 |
| 模型 | 仅字符串输出。部署为该预测命中的 DeployedModel 的模型的资源名称。 |
| 模型版本ID | 仅字符串输出。部署为该预测命中的 DeployedModel 的模型的版本 ID。 |
| 型号显示名称 | 仅字符串输出。部署为此预测命中的 DeployedModel 的模型的显示名称。 |
嵌入请求示例
Vertex AI PaLM Embedding API 执行在线(实时)预测,以从输入文本中获取嵌入。
该 API 最多接受 3,072 个输入标记并输出 768 维向量嵌入。
复制配置了您的项目 ID 的示例嵌入请求。将提示粘贴到 Cloud Shell 中以查询模型以生成文本嵌入。获取文本嵌入
MODEL_ID="textembedding-gecko"
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID?}:predict -d \
$'{
"instances": [
{ "content": "What is life?"}
],
}'方式三:Google AI Studio
要使用 Google AI Studio 使用 Gemini,您需要:
- 访问 Google AI Studio 网站。
- 注册 Google AI Studio 帐户。
- 创建一个 Gemini 项目。
注册和使用 Gemini 的注意事项
- Gemini 模型目前处于早期访问阶段,仅限于符合条件的用户使用。
- Gemini 模型需要使用 Google Cloud 的计算资源,因此您需要支付相应的费用。