
适合哪些人使用?
LinkedIn资料提取与JSON简历生成器是一个高效的工作流程,它利用Bright Data的基础设施从LinkedIn抓取专业资料数据,然后通过Google Gemini将这些数据转换为清晰、结构化的JSON简历。该工作流程非常适合自动化简历解析、候选人分析或集成到招聘平台中。
这个工作流程专为以下人群设计:
-
人力资源专业人士和招聘人员,用于自动化简历筛选
-
人才招聘平台,用于丰富候选人资料
-
开发者和AI构建者,用于创建简历解析AI流程
-
从事劳动力市场分析的数据科学家
-
通过公开数据分析潜在客户的增长黑客
这个工作流程解决了什么问题?
将简历或LinkedIn资料解析为机器可读格式通常是一个手动且容易出错的过程。大多数抓取工具要么因为反机器人保护而失败,要么返回难以处理的无结构HTML。
这个工作流程通过以下方式解决了这些问题:
-
使用Bright Data的Web Unlocker进行可靠、无验证码的LinkedIn抓取
-
通过Google Gemini LLM提取干净的文本和结构化资料数据
-
自动生成符合标准的JSON简历和技能列表
-
将简历发送到Webhook或存储以供后续使用
这个工作流程的功能
-
接收LinkedIn资料URL和必要的元数据(Bright Data区域、Webhook)
-
使用Bright Data Web Unlocker抓取LinkedIn资料
-
使用Google Gemini LLM提取干净的内容和技能
-
按照JSON简历模式构建JSON格式的简历
-
通过Webhook通知发送JSON简历
-
通过将文件保存到磁盘来持久化输出
设置步骤
- 在Bright Data注册。
- 导航到Proxies & Scraping,在Scraping Solutions下选择Web Unlocker API,创建一个新的Web Unlocker区域。
- 在n8n中,在Credentials下配置Header Auth账户(Generic Auth Type: Header Authentication)。
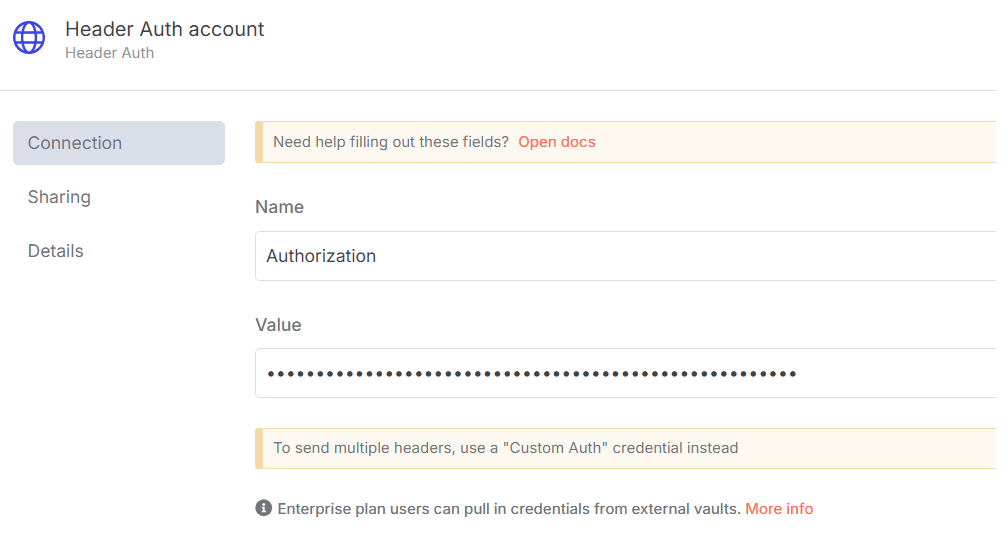

Value字段应设置为
Bearer XXXXXXXXXXXXXX。XXXXXXXXXXXXXX应替换为Web Unlocker Token。 - 在n8n中,使用Google Gemini API密钥配置Google Gemini(PaLM) Api账户(或通过Vertex AI或代理访问)。
- 更新Set URL and Bright Data Zone节点,填入LinkedIn资料、Bright Data区域和Webhook通知URL。测试时,可以使用https://webhook.site/获取Webhook URL。
如何根据需求自定义工作流程
添加语言翻译
插入一个翻译LLM节点以支持多语言资料。
生成PDF简历
使用HTML-to-PDF模块将JSON转换为格式化的PDF简历。
推送到ATS或CRM
添加集成节点将数据导入申请人跟踪系统(ATS)、CRM或数据库。
使用替代LLM
如果愿意,可以将Gemini替换为OpenAI或Anthropic Claude。