
适用人群
Bright Data Web Scraper的异步结构化批量数据提取工作流专为数据工程师、市场研究人员、竞争情报团队和自动化开发人员设计,他们需要通过编程方式使用Bright Data的数据集和快照功能从网络上收集和构建大量数据。
此工作流适用于:
-
数据工程师 – 从网络源构建大规模ETL管道
-
市场研究人员 – 收集批量数据以分析竞争对手或产品
-
增长黑客和分析师 – 挖掘结构化数据集以获取洞察
-
自动化开发人员 – 需要可靠的快照触发抓取器
-
产品经理 – 使用实时网络信息监督数据驱动的决策
此工作流解决的问题
大规模网页抓取通常需要异步操作,包括等待数据准备和快照完成。手动处理此过程可能导致超时、错误或结果不一致。
此工作流自动化了整个抓取请求提交、等待快照、检索数据以及通知下游系统的过程,并以结构化、可重复的方式完成。
它解决了:
-
异步快照完成处理
-
使用Bright Data可靠检索大型数据集
-
通过Webhook自动交付抓取结果
-
磁盘持久化以支持追溯或历史分析
工作流功能
-
设置Bright Data数据集ID和请求URL:接收数据集ID和用于触发抓取任务的Bright Data API端点
-
HTTP请求:向Bright Data API发送认证请求以启动抓取快照任务
-
等待快照准备就绪:实现循环或等待机制,检查快照状态(例如每30秒轮询一次)直到完成
-
下载快照:快照准备就绪后下载结构化数据集
-
将响应持久化到磁盘:将数据集保存到磁盘以供存档、审查或本地处理
-
Webhook通知:将最终结果或其摘要发送到外部Webhook
设置步骤
- 在Bright Data注册。
- 导航至Proxies & Scraping,在Scraping Solutions下选择Web Unlocker API创建新的Web Unlocker区域。
- 在n8n中,在Credentials(Generic Auth Type: Header Authentication)下配置Header Auth账户。
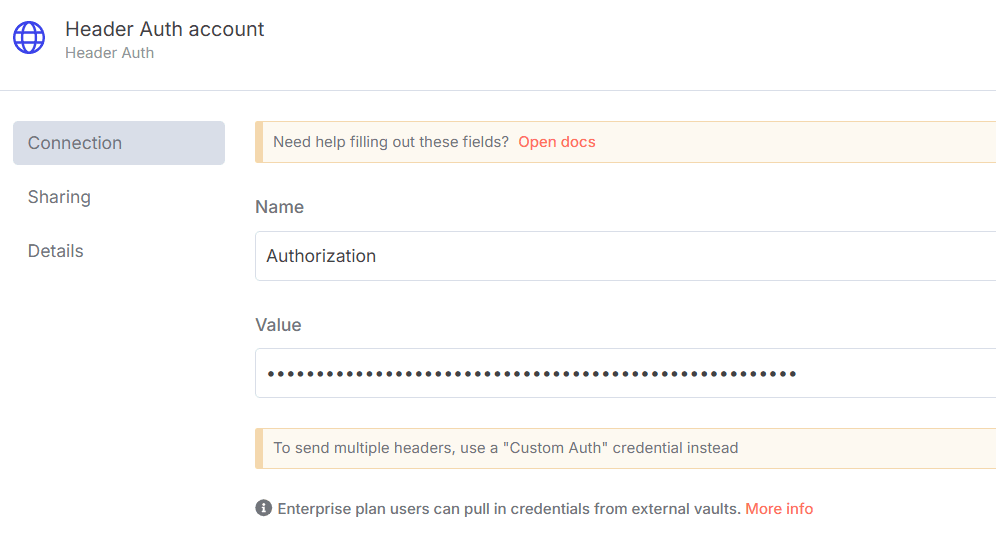

Value字段应设置为
Bearer XXXXXXXXXXXXXX。XXXXXXXXXXXXXX应替换为Web Unlocker Token。 - 更新Set Dataset Id, Request URL以设置品牌内容URL。
- 使用您选择的Webhook端点更新Webhook HTTP Request节点。
如何根据需求自定义工作流
-
轮询策略:根据快照复杂性调整轮询间隔(例如每15-60秒)
-
输入灵活性:从Webhook触发器或输入表单动态接收datasetId和请求URL
-
Webhook输出:将通知发送至 –
-
内部API – 用于仪表板
-
Zapier/Make – 用于多步骤自动化
-
-
持久化
-
将输出保存至:
- 远程FTP或SFTP存储
- Amazon S3、Google Cloud Storage等
-