
加州大学欧文分校和麻省理工学院的科学家表示,人工智能的碳足迹并不是一成不变的,他们今年早些时候在开放获取网站 arXiv.org 上发表了一篇论文,该论文改变了生成式人工智能模型的能源使用假设,并在上周引发了领先的人工智能研究人员和专家的争论。
该论文发现,在生成一页文本时,ChatGPT 等人工智能系统排放的二氧化碳当量 (CO2e) 比人类少 130 至 1500 倍。
同样,在创建图像的情况下,Midjourney 或 OpenAI 的 DALL-E 2 等 AI 系统的二氧化碳排放量减少了 310 至 2900 倍。
该论文的结论是,使用人工智能有可能以比人类低得多的排放量完成几项重要活动。
然而,人工智能研究人员本周对该论文的反应正在进行的对话也强调了解释气候、社会和技术之间的相互作用如何带来巨大的挑战,需要不断重新审查。
从区块链到人工智能模型,需要衡量环境影响
在接受 VentureBeat 采访时,该论文的作者、加州大学欧文分校教授比尔·汤姆林森 (Bill Tomlinson) 和唐·帕特森 (Don Patterson) 以及麻省理工学院斯隆管理学院访问科学家安德鲁·托兰斯 (Andrew Torrance) 就他们希望衡量的内容提供了一些见解。
汤姆林森表示,这篇论文最初发表于三月份,已提交给研究期刊《科学报告》,目前正在接受同行评审。
研究作者分析了有关人工智能系统、人类活动以及文本和图像制作对环境影响的现有数据。这些信息是从研究人工智能和人类如何影响环境的研究和数据库中收集的。
例如,他们使用了基于 1000 万个查询流量的 ChatGPT 非正式在线估算,每天产生大约 3.82 公吨 CO2e,同时还摊销了 552 公吨 CO2e 的训练足迹。此外,为了进一步比较,他们还包含了来自名为 BLOOM 的低影响力法学硕士的数据。
在人类方面,他们使用了美国(15 公吨)和印度(1.9 公吨)平均每年碳足迹的例子来比较估计时间内排放量对人均的不同影响需要写一页文字或创建一张图像。
研究人员强调了测量人工智能等不同活动的碳排放量的重要性,以便为可持续发展问题的政策制定提供信息。
帕特森在接受 VentureBeat 独家电话采访时表示:“如果没有这样的分析,我们就无法就如何指导或治理人工智能的未来做出任何合理的政策决定。” “我们需要某种扎实的信息,一些我们可以采取下一步行动的数据。”
汤姆林森还强调了激发他们工作灵感的个人问题,并解释说“我希望能够生活在地球环境可以支持的范围内”。 “也许使用[人工智能]作为一种创意媒介,不会造成很大的伤害……但如果它造成很大的伤害,我将停止做人工智能工作。”
帕特森围绕他们之前对区块链技术的分析添加了一些背景信息。 “工作量证明算法对环境的影响已经多次出现在新闻中。因此,我认为考虑环境影响以及其他真正巨大的全社会工具(例如大型语言模型)是一种自然的发展。”
当被问及可能改变论文中令人惊讶的结果的变量时。汤姆林森承认存在“反弹效应”的可能性,即更高的效率会导致使用量的增加
他设想“在这个世界中,我们所观看或消费的每一种媒体都会动态地适应你的确切喜好,这样所有的角色看起来都有点像你,音乐也稍微符合你的口味,所有的主题都稍微符合你的口味。”以各种不同的方式重申您的偏好。”
托伦斯指出,“我们生活在一个复杂系统的世界。复杂系统不可避免的现实是这些系统的结果是不可预测的。”
他将他们的工作定义为考虑气候、社会和人工智能“不是一个、不是两个,而是三个不同的复杂系统”。他们发现人工智能可以降低排放“对许多人来说可能令人惊讶”。然而,在这三个相互冲突的复杂系统的背景下,人们错误地猜测答案是完全合理的。
正在进行的辩论
本周,这篇论文在人工智能社区中引起了更多关注,Meta Platforms 的首席人工智能科学家 Yann LeCun 在他的 X 社交帐户(以前称为 Twitter)上发布了该论文的图表,并用它来断言“使用生成式人工智能生成文本或图像会产生文本或图像”。比手动或在计算机的帮助下减少3 到 4 个数量级的二氧化碳排放量。”
这引起了对该研究将人类碳排放量与人工智能模型进行比较的方法论的批评者的关注和反对。
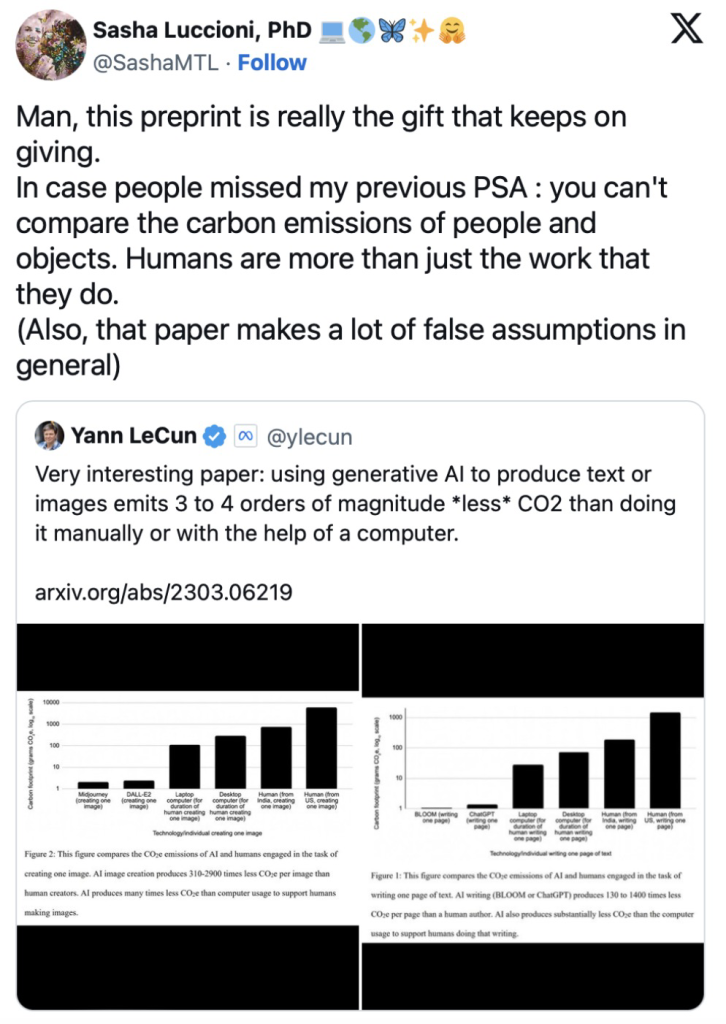

HuggingFace 的人工智能研究员兼气候主管 Sasha Luccioni 在接受 VentureBeat 电话采访时表示:“你不能只估算一个人一生的总碳足迹,然后将其归因于他们的职业。” “这是第一个没有意义的基本问题。第二件事是,将人类足迹与生命周期评估或能源足迹进行比较是没有意义的,因为我的意思是,你不能将人类与物体进行比较。”
生命周期分析仍处于早期阶段,现实世界数据仍然稀缺
在量化人类排放时,帕特森承认“进行任何类型的总能量消耗分析都很困难,因为一切都是相互关联的。”汤姆林森同意必须设定界限,但他认为“有一个叫做生命周期评估的整个领域,我们在同行评审的论文中更多地参与了这个领域。”
HuggingFace 的 Luccioni 同意这项工作必须完成,但研究作者采取的方法是有缺陷的。卢奇奥尼指出,除了直接比较人类和人工智能模型的直率方法外,准确量化这些环境影响的实际数据仍然是隐藏的和专有的。她还指出,也许有些讽刺的是,研究人员利用她的工作来衡量 BLOOM 语言模型的碳排放量。
如果无法获取有关硬件使用、能源消耗和能源来源的关键详细信息,就不可能估算碳足迹。 “如果你遗漏了这三个数字中的任何一个,那么它就不是碳足迹估算,”卢奇奥尼说。
最大的问题是科技公司缺乏透明度。 Luccioni 解释说:“我们没有任何有关 GPT 的信息。我们不知道它有多大。我们不知道它在哪里运行。我们不知道它消耗了多少能量。我们对此一无所知。”如果没有开放的数据共享,人工智能的碳影响将仍然不确定。
研究人员强调对这些复杂问题采取透明、基于科学的方法,而不是提出未经证实的主张。托伦斯表示,“科学是提出和回答问题的一种商定的方法,并附带一套透明的规则……我们欢迎其他人用科学或他们喜欢的任何其他方法来测试我们的结果。”